
Bonne nouvelle pour les bidouilleurs : une démonstration publique confirme qu’un Pentium II et 128 Mo de RAM suffisent à faire tourner un petit modèle inspiré de Llama. Ce n’est pas de la magie, mais une combinaison d’optimisation logicielle et d’astuces très concrètes.
Un vieux PC exhumé d’eBay
Tout a commencé avec l’achat d’un ordinateur sous Windows 98, chiné pour environ 119 £ (prix d’annonce : 118,88 £).¹
Problème : la machine n’acceptait ni les périphériques USB testés, ni les supports modernes. Les fichiers (poids du modèle, code d’inférence) ont donc été transférés via FTP en Ethernet depuis un Mac récent — une solution parfaitement compatible avec Windows 98.²
Compiler du code moderne… sur une machine d’un autre âge
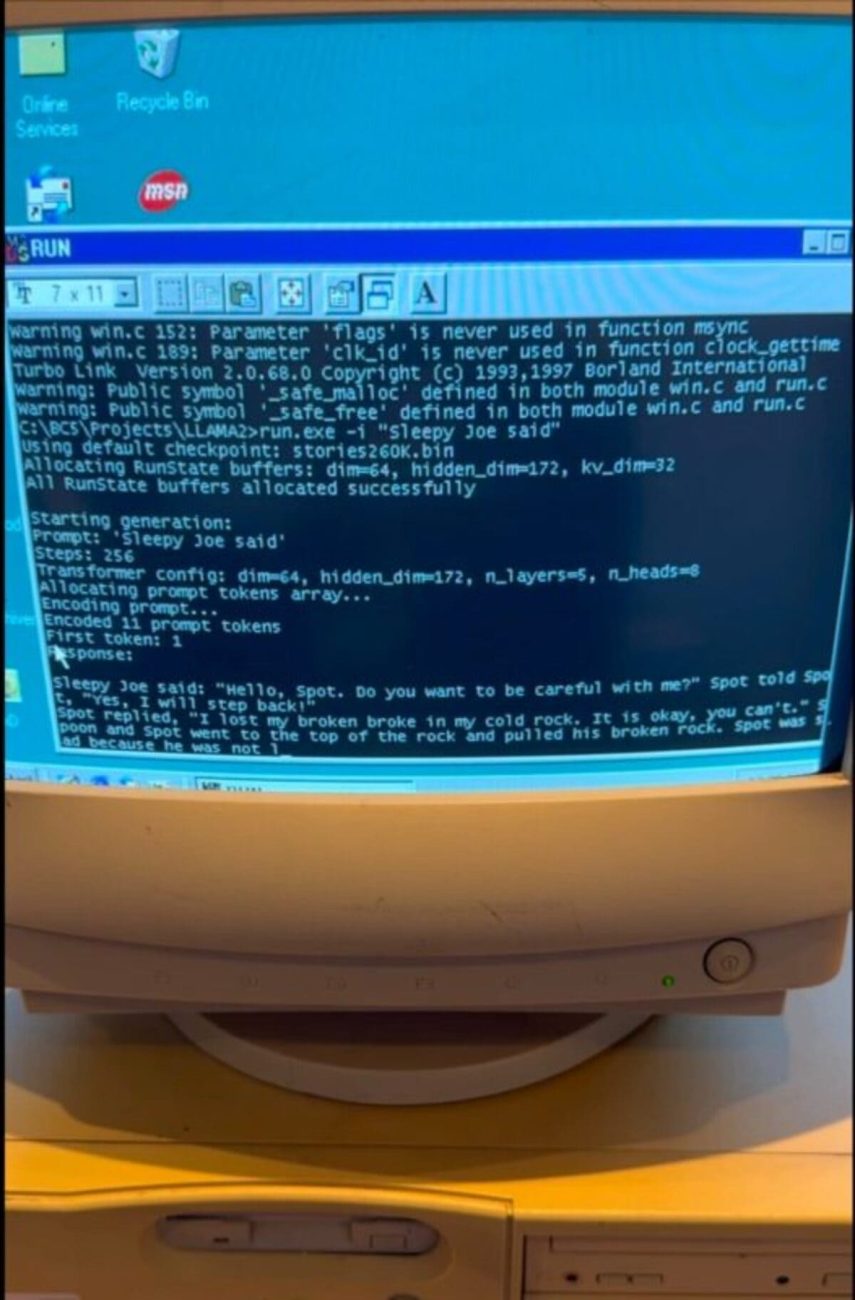
Restait l’écueil de la compilation. Les outils actuels échouant sur ce système, les auteurs sont revenus à Borland C++ 5.02 (1997), puis ont adapté le minimaliste llama2.c (≈ 700 lignes de C pur, d’Andrej Karpathy) : types revus, déclarations regroupées en début de fonction, simplification des E/S disque. Résultat : la plus petite variante (≈ 260 000 paramètres) a atteint ≈ 39,31 tokens/s, tandis qu’une version ≈ 15 millions de paramètres tournait à ≈ 1,03 token/s — lent, mais fonctionnel.³
Le saviez-vous ?
Sur ces démonstrations, un token/s n’équivaut pas à un mot/s : un mot peut représenter plusieurs tokens (sous-unités). Les vitesses rapportées sont donc des ordres de grandeur utiles pour comparer des réglages… pas une promesse de confort d’usage.

Le secret : une architecture plus sobre
Derrière l’enthousiasme, une idée structurelle : BitNet, une famille d’architectures où les poids sont ternaires (−1, 0, +1), soit 1,58 bit par poids (log₂ 3). Cette frugalité réduit fortement calculs et mémoire. À titre de repère : un modèle 7 milliards de paramètres occupe ≈ 14 Go en 16 bits (ou ≈ 7 Go en 8 bits), quand une version BitNet de taille équivalente descend autour de 1,38 Go.⁴
Vers une IA pour tous ?
L’expérience du Pentium II rappelle que l’IA n’a pas toujours besoin de fermes de serveurs : des modèles sobres peuvent vivre sur du matériel ancien ou modeste, pour de l’embarqué, de l’éducation ou de la recherche. Reste l’angle énergétique : selon l’Agence internationale de l’énergie, la consommation électrique des centres de données dans le monde pourrait plus que doubler d’ici 2030 (≈ 945 TWh), l’IA étant un moteur majeur de cette hausse.⁵
En somme, ce tour de force n’est pas qu’un clin d’œil rétro. Il rappelle qu’en optimisant l’algorithme et la chaîne logicielle, on peut abaisser les seuils matériels… et élargir l’accès à l’IA, sans dérapage de la facture énergétique.
Notes de bas de pages
- Running Llama on Windows 98 — EXO Labs (Day 4) — https://blog.exolabs.net/day-4/
- Ibid. (transfert FTP sur Ethernet, périphériques PS/2) — EXO Labs — https://blog.exolabs.net/day-4/
- Résultats (≈ 39,31 tok/s en 260 K ; ≈ 1,03 tok/s en 15 M) — EXO Labs + reprise média — https://blog.exolabs.net/day-4/ ; https://www.tomshardware.com/tech-industry/artificial-intelligence/ai-language-model-runs-on-a-windows-98-system-with-pentium-ii-and-128mb-of-ram-open-source-ai-flagbearers-demonstrate-llama-2-llm-in-extreme-conditions
- BitNet b1.58 (poids ternaires ; 1,58 bit/poids) — Microsoft Research — https://www.microsoft.com/en-us/research/publication/the-era-of-1-bit-llms-all-large-language-models-are-in-1-58-bits/ ; repères de tailles LLaMA 2 7B (≈ 14 Go FP16, ≈ 7 Go en 8 bits) — BytePlus — https://www.byteplus.com/en/topic/464549 ; EXO (≈ 1,38 Go pour un 7B BitNet) — https://blog.exolabs.net/day-4/
- IEA — Energy & AI : demande d’électricité des data centers plus que doublée d’ici 2030 (~ 945 TWh) — https://www.iea.org/news/ai-is-set-to-drive-surging-electricity-demand-from-data-centres-while-offering-the-potential-to-transform-how-the-energy-sector-works ; rapport de fond — https://www.iea.org/reports/energy-and-ai/energy-demand-from-ai